Since this is around the second anniversary for wowtoken.app, I thought I should do an update detailing a lot of the work that’s been done between when I wrote the first article and now.
Beyond the usual dependency updates and small UI improvements, most of the big changes have happened under the hood.
Introducing Lambda@Edge
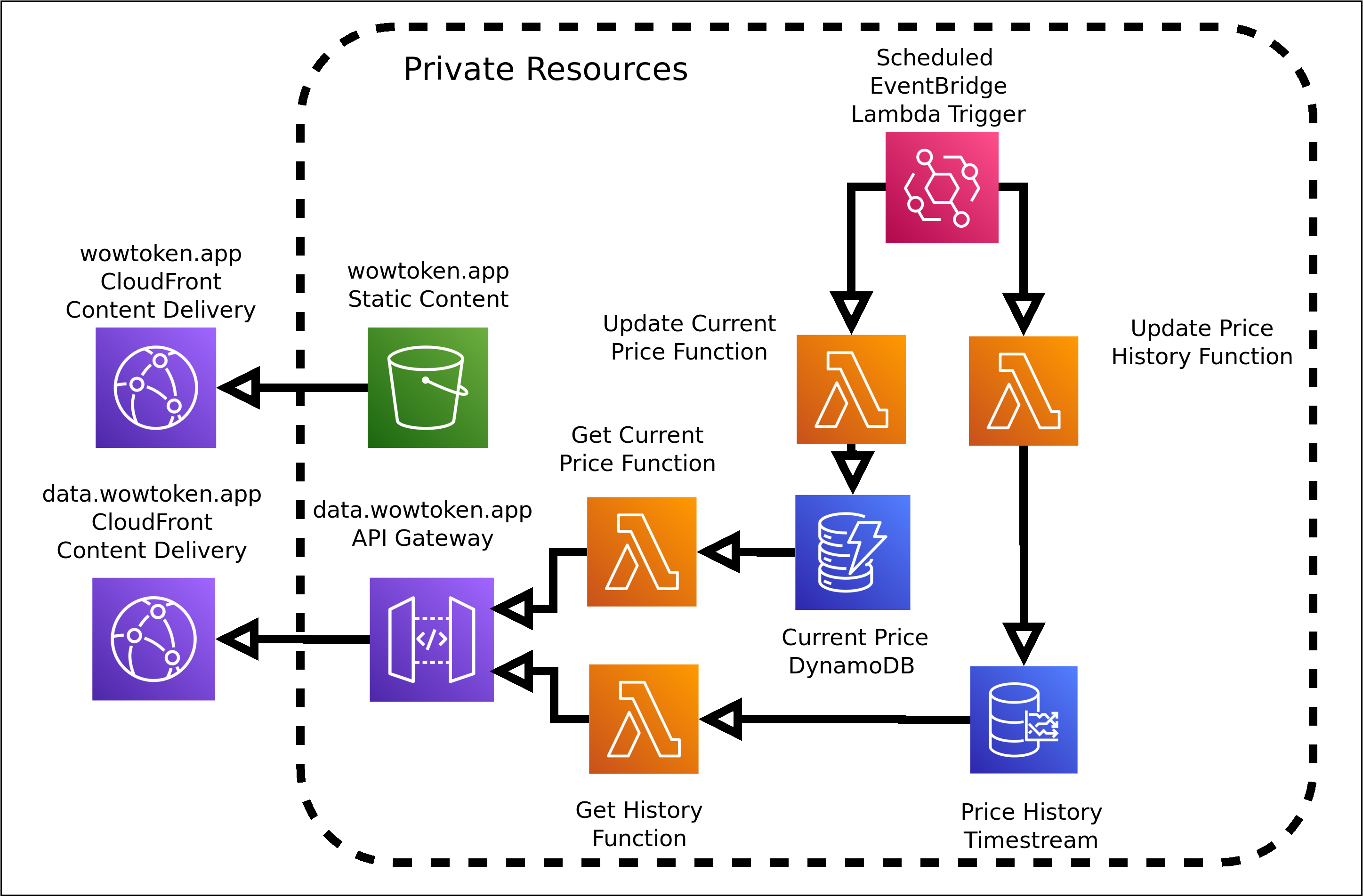
For a long time, I have wanted to fully utilize the power of Functions as a Service, but originally pigeonholed myself into using us-east-1. The original rendition of the data providers that generate the responses for data.wowtoken.app (the API) were written in my favorite language, Ruby.
This was done mainly because when I was originally learning how to use Lambda, I didn’t want to have to think about specific language abstractions, when Ruby’s come most natural to me.
The issue is Ruby is kind of a second-class citizen on Lambda. They do support it as a runtime, but you are limited to 2.7, Ruby is only available in a handful of zones (at least, last I checked), and furthermore and most crucially is not available for use with Lambda@Edge.
However, Python is a first-class citizen (along with NodeJS), so after a quick rewrite of the function into Python (and some much-needed refactoring), we were good to go.
Now before we go any further, I should give a little background to Lambda@Edge if you are completely unfamiliar. Where Lambda is a scalable function in a single region, Lambda@Edge takes that function and runs it much closer to where your users are, at the CloudFront Points of Presence closest to them.
There are a few advantages to this, the main one being speed in the form of much reduced latency.
While the speed of light in fiber is fast, it takes a noticeable amount of time for a packet of information to make a trip there and back. Even across the US it can be impactful for some applications (think online games and VoIP), and that’s under best case scenario. Including last-mile situations such as DSL and cellular, that can add even more overhead. All that gets multiplied when TCP does it’s handshake. As well as SSL. Very quickly what is only 150ms ping time can become seconds of waiting for a page to load.
The solution to this (most of the time, I am not talking about the edge case of you wanting to talk to your friend directly on the opposing side of the globe), is to move your compute closer to your users.
Lambda@Edge makes this easy, and with one click of a button you can deploy your function worldwide.
But moving the compute closer to the end user was only half the battle. As it stood, all the data was still getting sourced from DynamoDB (and Timestream, but we will come back to it later).
DynamoDB Global Tables
DynamoDB had long been my backing for both the current token price and more recent historical data as it’s performance was more than adequate for this application. One of the neat features it has is the easy ability to set up what is essentially eventually consistent Active-Active replication.
With one click of a button in the console, you can replicate a DynamoDB table to any region you have access to. This makes the other part of the puzzle, data locality, very easy for the >90% of requests going to it.
With the two puzzle pieces now in our hands, we needed to combine them to make the magic happen.
The solution I came up with for this is a simple hash map, which I hand mapped regions to the closest Dynamo Global Table, with a failover to the most likely-to-be-closest table if the region the function is running in isn’t in the map. It’s not elegant and I would like to do another pass at it, but it works.
There is no real reason to run Dynamo Global Tables in more than a handful of regions unless you have specific constraints to take into consideration (the main one I can think of is wanting to reduce intra-region data transfer costs if you are moving a lot of data – this app is not).
Currently I am utilizing several replicas in the US, as well as Paris, Sydney, Tokyo, Stockholm, and Sao Paulo. I feel like this covers most scenarios where traffic for this app would be coming from, and means the latency from Lambda → DynamoDB should never be more than 50ms for most regions, and should be much lower than that for a vast majority of my users.
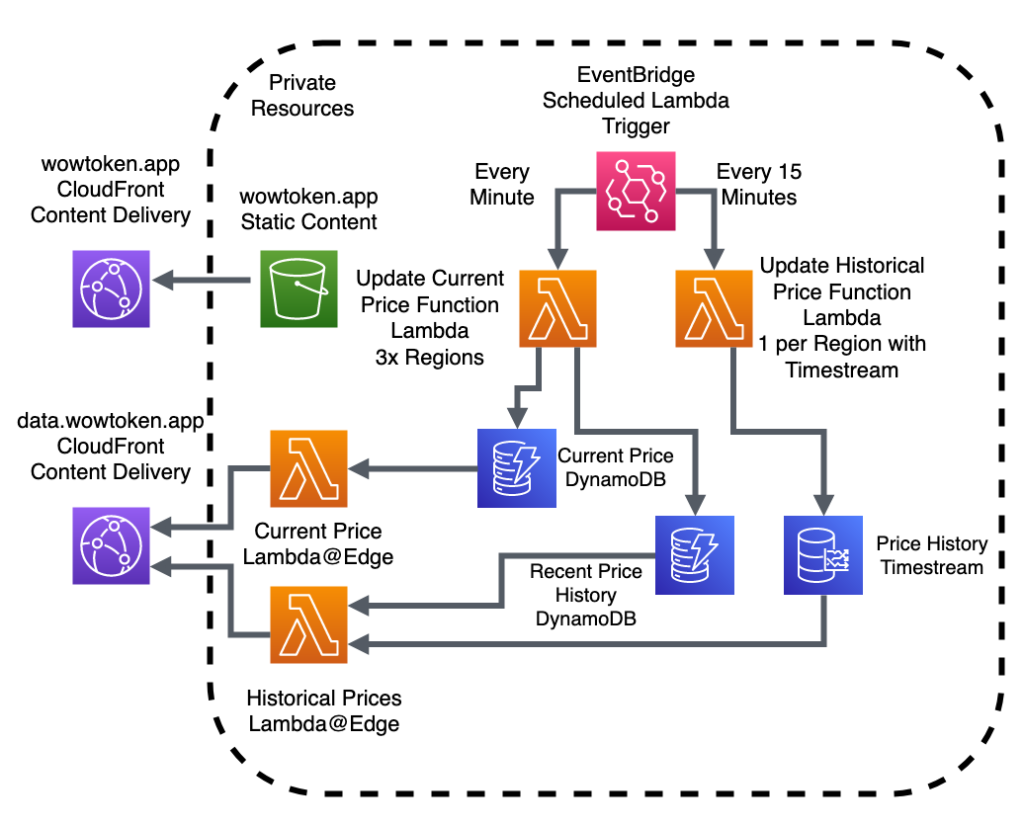
Global Timestream
While I wish Timestream was as easy as a click of a button to make it a global service, it still has a long way to mature. This means replication will have to be handled by your application in one way or another. Otherwise, it does what it is meant to do pretty well, but with the other caveat of the long response time to a query, even for “in memory” data. So for the historical data, I took a multi-pronged approach.
As seen from it’s great job responding to the current price, DynamoDB has an excellent response time – at least for the use case of a web browser requesting data – and was identified as a good candidate to be used in addition to Timestream for a hybrid approach.
Given most people are looking at the the last few days, up to a month or so, a new “historical” DynamoDB table was created to hold the previous few weeks of data. This ended up working so well, the expiry column has been updated from a few weeks, to a month, to three, and now to a full year of data (though this is still being filled).
This means most requests will benefit from the data locality of many DynamoDB Global Table replicas, but that still leaves the older historical data, whose response size would not fit into a single DynamoDB response page, nor is stored in DynamoDB.
For a long while, it had been served from a single location, a Timestream database in us-east-1. However, I was running into exceptionally poor response time for large queries that happened from locations that were not in the Americas. Multiple seconds of waiting, which makes for a very poor experience. While this was somewhat alleviated by upping the Max-Age in the cache, it was a band-aid at best, as cache misses still have to wait.
The proper solution to this is to have multiple Timestream replicas in multiple regions. Like I alluded to in the first paragraph of this section, Timestream has no support for replication built in, so it had to be implemented on the application layer.
Unfortunately, Timestream is (still) only available in a handful of regions, though thankfully those are fairly geographically diverse. In order to bring these up to speed with the original though, required backfilling data, which until pretty recently, was not super trivial on Timestream (they used to only let you backfill up to what you had your “in memory” table section had, this restriction has since been removed).
This involved retrieving all the data from the current table (which required some clever Timestream queries to get it back in it’s original form, otherwise responses were too big for Timestream), turning on the EventBridge trigger for the new regions so they can start storing the latest data, and writing a simple script to slowly backfill the rest of the data.
Once the other regions were caught up, we could now enable traffic to them, implementing a similar solution to the DynamoDB smart-routing.
Top Speed?
We are reaching the point of chasing tails, and by that I mean tail latencies. CloudFront caches the static assets making up the actual web page (HTML, CSS, and JS) for a long time, as well as the Lambda generated responses for as long as we can be sure the data is still relevant, but what happens if you hit a cold CDN cache?
Absolute worst case for Lambda is a cold start, where the function hasn’t run recently at that PoP and has to be initialized first. The only real way around this is either keeping them warm using something along the lines of provisioned concurrency (honestly not even sure if that’s possible with Lambda@Edge – probably not; shows how much I weighed this solution EDIT: it’s definitely not a thing), or a lighter function a-la CloudFront Functions (which are Javascript only and even more limited). While I do utilize CloudFront Functions for some things unrelated to this, they were too limited for what I needed to do.
This didn’t seem like a tree worth barking up though as the cold-start latency for a Lambda@Edge function seems to be at worst one second. The one function where speed really mattered (the current cost) would be called often enough from any viewer where it was highly unlikely to be cold for most PoPs, and the function where it didn’t matter as much (the actual price history data) is cached for longer on the CDN anyways.
If, however, you are asking for the static assets, worst case scenario is it would have to reach out to the S3 bucket in us-east-1 and pass the response to you while warming it’s cache. That’s still a negative experience, ideally the site should be loaded and making API calls in less than a second.
This is the area I have been actively looking at solving as I write this. The most likely candidate is using a S3 Multi-Region Access Point with buckets distributed to key regions to reduce TTFB latency for cold-cache hits. This works in conjunction with CloudFront to source the static assets from a location much closer to the requester.
The main blocker to implementing this now is figuring out how to integrate it with the build system, but that’s a problem for future me. For now, I can just increase the Max-Age of the cache to keep the assets in for longer, and utilize wildcard invalidations when I make API breaking or high priority updates (which is very rare).
If you read this far, thank you for sticking along, and have a cookie. I’ll likely have more updates in the future detailing future engineering efforts, but as it was a year and a half since my first post, I wouldn’t expect them too often.