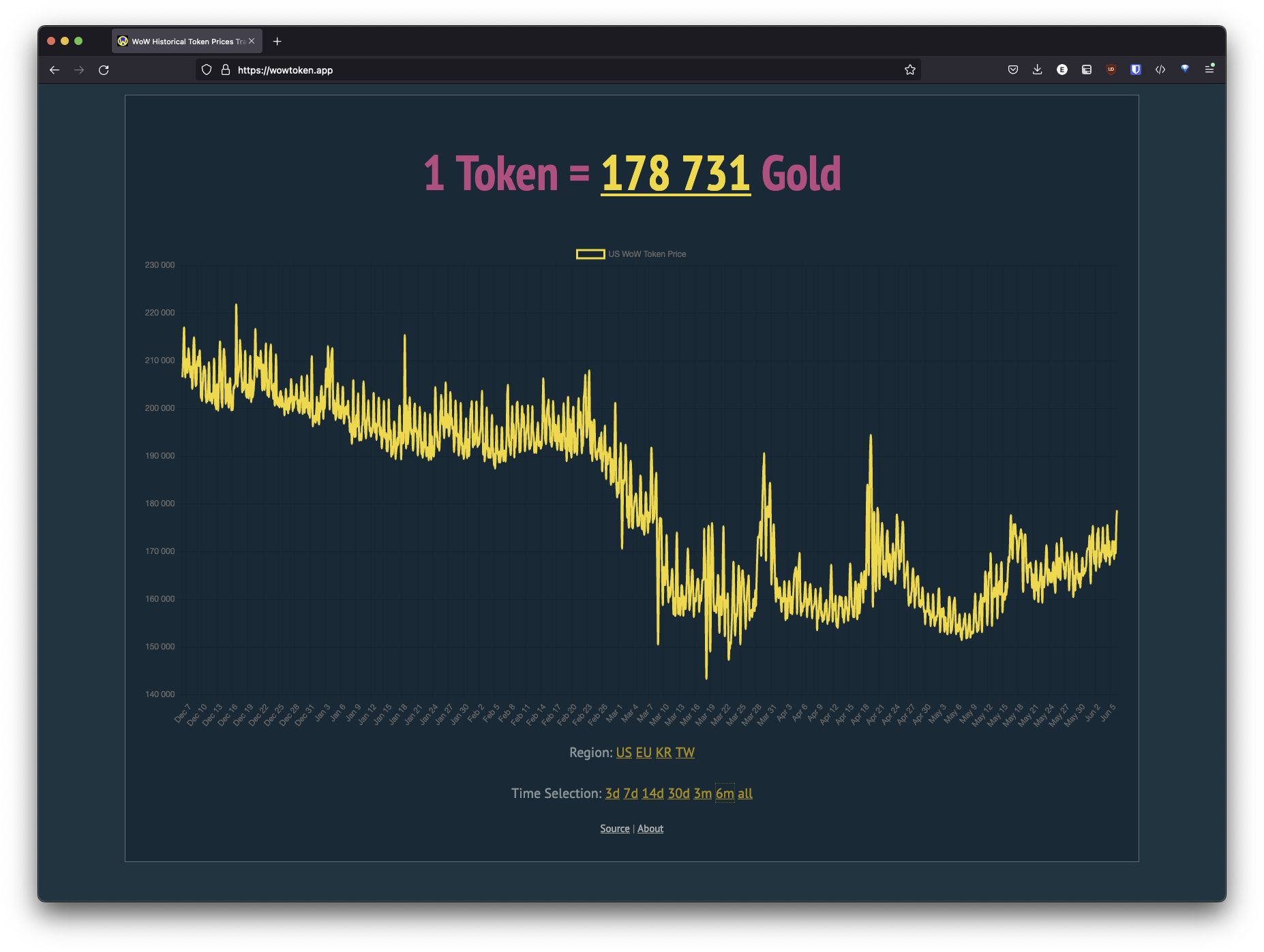
I have been playing World of Warcraft, the hugely popular MMORPG from Blizzard Entertainment, for years now, as I enjoy the social and team effort aspects of raiding the hardest content in the game. Having spent so long in the game, I have touched basically every corner the game has to offer. One of the main aspects of the game is the economy, driven by gold.
Nearly everything you do in the game generates or spends gold. Being able to capitalize on any of the markets can garner you a lot of gains, and having the ability to visualize various aspects can allow you to make data-driven decisions where you’d be basically blind without it.
A few expansions back, Blizzard implemented the WoW Token system in the game to try and help cut down on the real-money trading gold sellers that nearly all MMOs have to deal with. They decided the best way was to become the first-party market for both sides of the transaction, and they take 25% on top.
The result of this means that people who don’t have time to grind out gold in game can spend $20 and get a fluctuating amount of gold, or vice-versa, where you can spend gold and either redeem it for game time (as normally it costs ~$15/mo to play), or for $15 in Blizzard balance that you cane spend on other Blizzard properties.
Given that they essentially created a market, the price of the token is driven by the supply and demand of each side of the equation. There are both daily fluctuations in price, and longer-term moves in the daily average. Having an informed decision on when to make a token transaction can mean the difference in tens to hundreds of thousands in gold spent or gained.
Blizzard is one of the few game developers that offer a rich API to export information about the game world. They have lots of interesting bits of information available, and one of those is the current value of that WoW Token.
The old site that I used to keep track of this died out of the blue. I am not sure if the domain expired, or what, but I decided this would be a good time to develop my own to my liking, and a fun way to get into using the API.
Design
The goal was simple. Display the current price of the token, with an arbitrary amount of history available to view. I wanted as little infrastructure as possible, because I didn’t want this site to die or to have to worry about servers for it. Given my previous experience with AWS, it was the natural choice to deploy there, and at the time they had just released their Timestream service to the public which was a perfect fit for this.
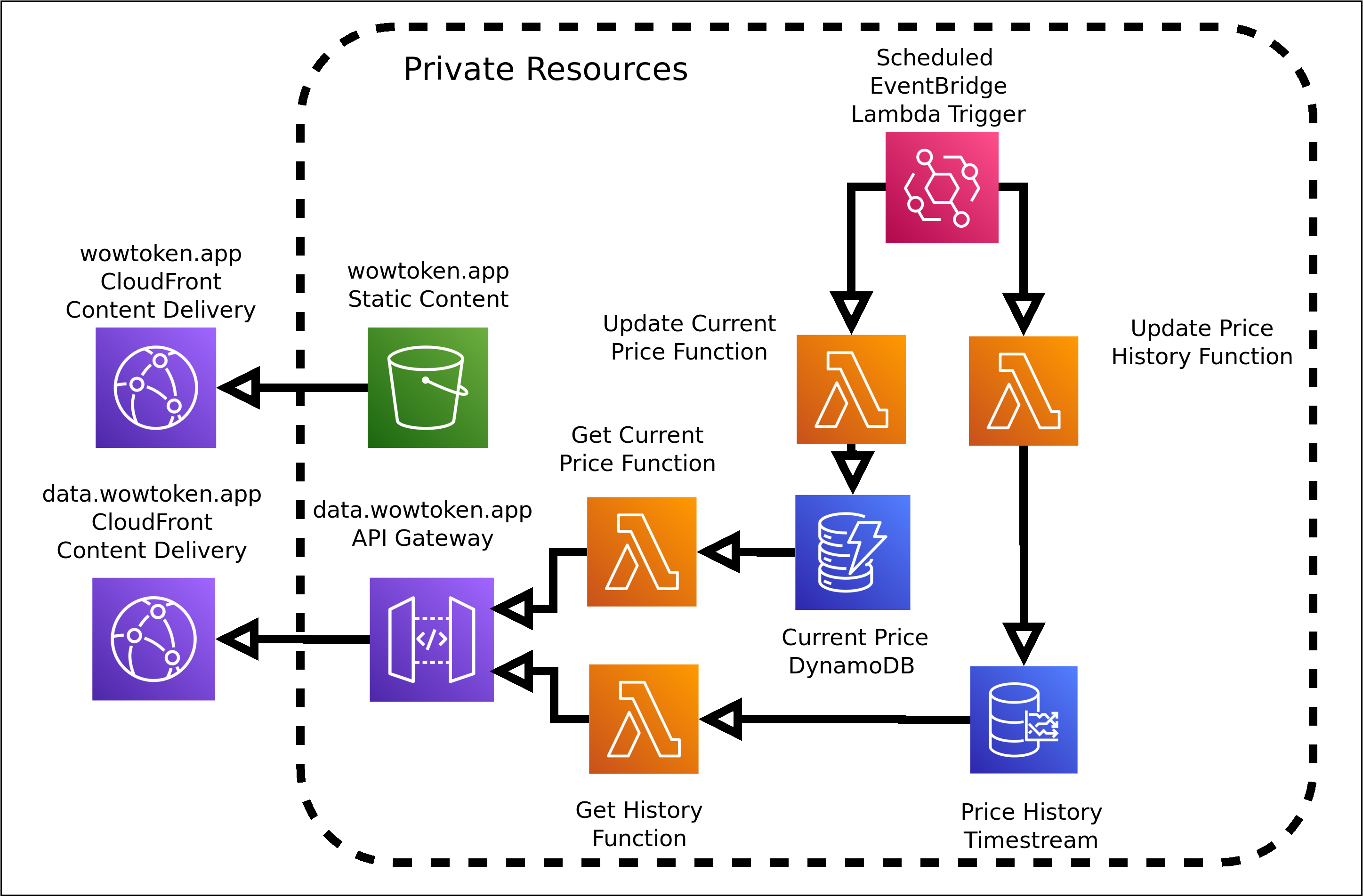
A time-series database by itself wont do anything by itself though, so AWS Lambda was chosen to drive the dynamic bits, and DynamoDB for the current price (as polling Timestream takes significantly more time compared to DynamoDB). EventBridge was chosen to trigger the Lambdas to update the price in DynamoDB and Timestream.
The token price itself only updates a few times an hour, but the timing is fairly arbitrary, so once a minute was chosen as a poll interval for the current price, and once every 5 minutes for the Timestream record.
I wanted to write the front end nearly from scratch, to be fairly lightweight, and just call a back end API to actually get the data. In the style of a Single Page App (SPA), but for this I didn’t need anything like React or Vue, as there needed to be only a few functions to handle getting the price and the current cost. CloudFront and S3 were chosen to front the static files, and CloudFront plus Lambda and API Gateway to handle the generated API responses.
This decision was made for a two-fold reason:
1) While the site was still in it’s infancy, I was unsure as to the amount of traffic it would get, and didn’t want to pay for an EC2 instance if it wasn’t being used at all.
2) I wanted this to be very scalable. Again, I was unsure as to the traffic patterns and didn’t want it to buckle as it got more traffic, and there was no reason it should have to hit the origin more than once a minute even under very high load.
Lambda itself is nearly infinitely horizontally scalable, as it will spin up more instances as it gets more traffic, but having a CloudFront distribution in front of it allowed responses to be cached for a configurable amount of time, this matching the poll rate of the the upstream API. API Gateway allows for a configurable routing and authorization for the API, and graceful fallback if for whatever reason the Lambda failed to process.
Worst-case scenario would be individual users all hitting different CloudFront servers, and those requests being forwarded to Lambda, and best case is they just hit the CloudFront server and the request doesn’t make it back to the origin.
In theory, this means the site gets faster as more people reach it. Responses should get cached closer to the users, and the Lambdas themselves stay “warm”, meaning fewer slow cold starts of a fresh Lambda instance.
Where possible, I use Ruby for my projects, as that’s what I enjoy writing the most. Lambda has native support for Ruby 2.5 and 2.7.
Implementation
The Battle.net API requires authentication, and is rate limited in the amount of requests per second and per hour you can hit it. This particular application should never run into the rate limiting, but since I have other projects in the works that use the API, the first step was to develop a API gateway for my application (not to be confused with the Amazon API Gateway service).
I wanted to stick the Unix philosophy of do one thing and do it well, so separating the authentication and rate limiting of the API to another function was the first step. One day I will write up about that project, but it’s currently being rewritten to a point that I am comfortable releasing it to the masses. Once it is, it will be available on GitHub here under the MIT license.
Next was developing the ingestion functions. I decided to do them separately, as the the time series data did not need to be the same time granularity as the current price, it was there to show trends, and since the token price only updated a few times an hour, 5 minute granularity was chosen to save costs. These functions are rather simple, as they take the data in one form and just spit it into DynamoDB if the price is different than the current, or in Timestream, regardless if the price changed.
Long term plans include analysis of the data, and in that case it’s better in this case to have a lot of more detailed data that can be reduced down if necessary, than to try and interpolate data that isn’t there.
Next was the “backend” data APIs, one to return the current price of the token from DynamoDB, and another to retrieve the last x hours from Timestream. These again are separate functions, and this was chosen so the requests could be made in parallel, as well as having different caching policies for each function. Running a Timestream query takes a bit longer than returning four keys from DynamoDB, and I wanted to be sure to render the current price as quickly as possible, whereas I was okay with the Timestream data taking a bit longer to return.
As an aside, when initially developing for Lambda, there was a learning curve and some frustration with the fact it felt like I could only verify the results of the execution by running it on Lambda itself. Sorta like a mainframe. However, since these were rather simple functions, the easiest way was to just unit test the method itself. The testing feature within the API gateway console itself is also useful to check what you uploaded ran correctly.
The main page itself was the easiest part, I had more trouble picking the colors I wanted over writing the functions that dealt with the data APIs. The biggest snag here was taking the output of my API into a format that Chart.js liked, but that was more due to me getting muddied down in the Chart.js documentation than anything else.
Deployment is easy, as each piece is separate, I just have CodePipelines that pull from GitHub when a component is updated. If there are no external dependencies and can be deployed as-is, such as the static front end, it’s immediately copied to S3 and that’s it. For the Lambdas that require dependencies, these are built and deployed via the Serverless Application Repository. Updates to the live site happen in less than 10 minutes in general.
Things I Learned
This project acted as a jump board to the rest of the Battle.net API. I am actively building out my next project, wowauctions.app, which is a spiritual successor to this. I learned a lot about how to build an SPA that interacts with Lambda, and this next project is being built with React.
I had only minimally interacted with Javascript before (basically dodged it as much as I could), so forcing myself to use it here taught me a lot about it, and helped me dive straight into React for my next project after I gathered the basics.
It taught me a lot about the various TSDBs offered, which I already wrote about here.
Getting things out the door is the hardest though. It’s easy to get invested for 75% of the project, only to put it down as soon as you are super close to finishing, and it was nice to see my original vision to the end.
The Future of the Project
There are a few things I want to add to the site, but it will take some refactoring of the the Lambdas. Right now, the maximum you can look at is the previous 7 days, but that’s purely for aesthetic reasons. I want to come up with a good way to bucket the data where you can still get an idea of the daily min/max, but also the daily moving average for historical data.
Right now, the data that gets returned from the function is basically every step or every time the price changed. Originally, it was returning all of the data, but this caused the graph to be very sharp. I wanted a smoother plot so the trend in price could be reckoned. However, if I apply this to 6 months, the amount of data looks quite bad represented in the graph as-is. I am still working on the best solution to this.
I also want to add add some light statistics about the data presented. Kind of like a stock or cryptocurrency has the current price compared to 24 hours ago.
I definitely want to explore using Lambda@Edge or similar to reduce latency for end users. Even shaving milliseconds off the response time is worth it. There is no reason this setup can’t be replicated to other regions.
Beyond that, I am undecided. The original goal was to be simple and fast. I don’t need to add unnecessary bloat. However, given it only costs a few dollars at most to run per month, there is little reason to ever let this die, at least as long as the game data APIs for World of Warcraft exist.