While purpose-built Time Series Databases (TSDBs) have been around for a while, they’ve been surging in popularity recently as people are realizing the value of data-over-time. I’ve been working on some personal projects that make heavy use of these databases, and I took some of the most popular for a spin so you can learn from my mistakes.
Most coding projects start with research – I know what my requirements are, so how am I going to fulfill them. When this initially began, my requirements were simple. I wanted to store the value of the World of Warcraft Token in the 4 different regions the main Blizzard API serviced. This had limited amounts of updates, the value changing at most every 15 minutes.
InfluxDB
InfluxDB is ranked highly on Google, and to their credit, it’s exceptionally easy to get started. Install, point your browser at a host:port combo and you are off to the races.

I had a prototype of what I wanted working in less than a day, and let me visualize the data I was storing in the Explore section with ease. However, when it came time to move this from development to initial deployment I ran came across the first roadblock. Replication/HA. Making sure my app is alive even if AWS AZ USE-1b is down. InfluxDB OSS edition allows no easy way to do this, which I guess is their way of getting you to use their paid software. There is a proxy that replicates writes available, but the implementation is up to you and there is no easy path to recovering a failed node.
For the token project, I had to go with a different TSDB, but fast-forward a few months I decided to pay InfluxDB a revisit. The next project I was working on had less availability requirements, which meant the first roadblock wasn’t a factor. I liked the rapid prototyping and immediate feedback with the visual Data Explorer page, so I forged ahead.
InfluxDB has a huge limitation I had seen the red flags of, but didn’t think I was going to run into. Due to the way the data is stored on disk and in memory, InfluxDB is great for data that doesn’t have high cardinality, and can suffer when there are a lot of unique data points. This is easy to see, here, here, and here and examples of where this point is stressed. The tokens, as an example, had 4 different combinations of keys for the values represented. My new project had many, many more. My lower-bounds estimate for the uniquely tracked points is around 1.7 million.
This is how you strangle an InfluxDB instance. Turns out, if Data Explorer tried to enumerate all the possible keys, the entire thing would lock up. systemctl stop influxdb would hang for a bit, before killing the process. I had to evaluate alternatives here too.
InfluxDB might be great for other use cases, but for the data I was tracking, it was not the play.
AWS Timestream
One of Amazon’s most recently launched products (as of this post, about 6 months ago), Timestream offers the benefits of being on the cloud, such as pay-as-you-go, and serverless architecture. As far as I am aware, this is the first of the big cloud services to offer a hosted TSDB, that’s not 3rd party software (for example TimescaleDB offers a cloud service that runs their database on a public cloud).
Other than data retention and splitting your data into Databases and Tables, the options are sparse. You get some ingestion and query graphs, and that’s about it.
Timestream manages the rest for you, including multi-AZ replication and high availability. It’s fairly easy to get started ingesting data (though I will say the data structure is kind of funky), and if you are familiar with SQL, it’s easy to query the data too.
Amazon highly suggests that you optimize your queries heavily to return the least amount of data necessary for your operation, namely to save on costs and bandwidth. And saving costs where you can is a must, because it’s pretty expensive. Not unreasonable for what you are getting (native multi-AZ replication, configurable in-memory or disk storage, auto-scaling for queries and ingestion), but far outside of my budget for the larger data set.
It was a perfect fit for the WoW Token website. The amount of data being stored was fairly small, and I didn’t want to host any servers for this project. I wanted it to be essentially autonomous, running on native AWS services. The database for this project costs me under a dollar a month to run, with most of the cost being my horribly un-optimized queries for what I am doing.
However, when I attempted to use Timestream for my other project the true costs of the service started to show. Since the AWS bill takes a few days to populate with new information, I ran it for 2 days to get an estimate to the monthly bill.
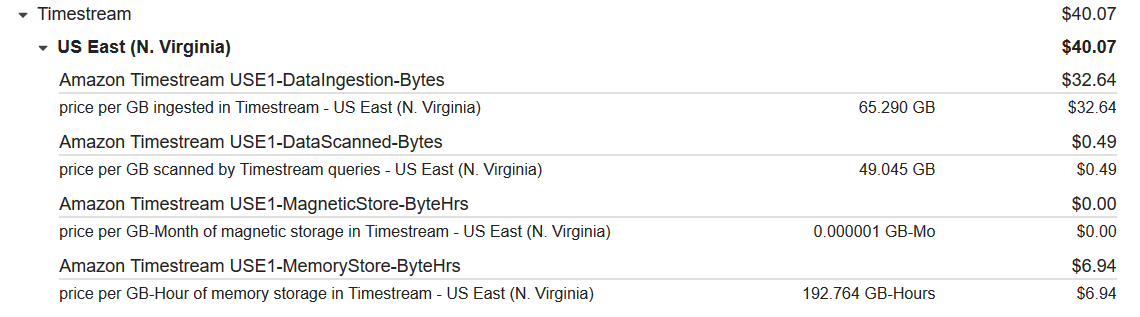
Yikes over $40 in 2 days, I did not want to be putting at least $500 a month towards a personal project I don’t even know if I will make a cent off of. I was not going to be able to use Timestream for this project.
TimescaleDB
Right below InfluxDB in the Google results sat software called TimescaleDB. When I made my first initial pass over the available software, I put this as low priority because it required the most steps get going with. I had to setup a Postgres database, and then install this on top as a library. But, after realizing how much Timestream would be, it began to look a lot more attractive.
I deploy where I can on AWS’s Graviton2 ARM instances, both because it’s the best price/performance in general in the EC2 lineup, and because I believe ARM has a stronger future and I want to support that by not using x86 where I can. InfluxDB had prebuilt ARM packages for Ubuntu, but as of when I last installed it TimescaleDB did not. There is an open issue for those, but I had to compile it from source, which worked fine.
Once I rewrote my workers to dump to what was essentially just a Postgres database, I was delighted to see excellent performance for the amount of data I was dumping into it. This was the choice for my larger project.
As my workers were off to the races, I started exploring what other neat features Timescale offered. The first to catch my eye was the compression feature, which boasted possible compression ratios of over 90% for related data.
It’s important to read the documentation carefully around the segmentby and orderby options in order to optimally compress your data. They do a far better job explaining the mechanisms behind it then I would ever hope to, but once I write up more about that project I’ll give more details about my specific usage as a real-world example.
It was easy to add compression as a migration for Rails, but be mindful it’s easier to compress than decompress, and the schema is essentially set once it is compressed, so it’s a one-way street in Rail’s eyes. I am sure you could add up/down migrations to automatically decompress chunks, but that was far too much for what I needed to do.
The compression ratios they claim are not wrong. It’s neat to see my database drop significantly in disk usage every 7 days (my chosen interval) as the compression task gets run for the last week. It looks like a big saw.
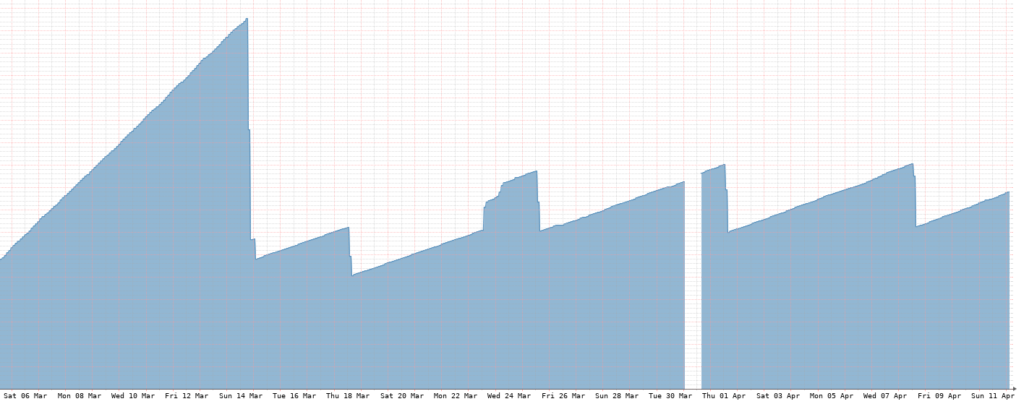
I have yet to reprovision the size of my EBS volume as the compression has kept it relatively small. The hot data is stored on SSDs, which while performant, also start to get expensive as you go up in size. I will probably double the size of the volume once or twice it gets to near full, but beyond that TimescaleDB has another feature to deal with less-used data.
It has the ability to move chunks of the (hyper)table to a slower medium of storage, like spinning disks. Running statements against this hybrid table is seamless, with relevant data pull from the slower drives where requested. I have yet to implement it on my project, given I haven’t needed to use it and it’s still a bit of a manual process. This allows you to free up space on your hot data drive, while maintaining that older, still-important data.
There are a few other TSDBs I came across, some open source, and others not, but for the data I am handling, I am very happy with the choices I made. Even if I didn’t go with all of them, it was a learning experience nonetheless.
Timestream is great for not dealing with servers and for the little amount of data I store on it, it’s very cheap compared to the rest of my AWS bill. But if you start to load it with a lot of data, it’s fairly expensive.
TimescaleDB on the other hand requires me to maintain a Ubuntu install with all the headaches included with that, but it’s exceptional performance, feature set, and it just being a layer on top of Postgres allows basically any ORM to be able to use TimescaleDB. I pay under $100/mo for this versus the $500+ estimated for Timestream.
InfluxDB was easy to get started with, but falls to it’s knees when you are dealing with high-cardinality data. I am sure it has it’s place, it seems to be very popular for monitoring systems where you don’t have 1.7 million+ possible combinations, but for those projects, it was not the right choice.